Einführung in Large Language Models (LLMs)
Large Language Models (LLMs) wie GPT-3, GPT-4 oder LLaMA revolutionieren viele Branchen. Sie schreiben Texte, beantworten Fragen und führen komplexe Analysen durch. Die zugrunde liegende Leistungsfähigkeit hängt entscheidend von der Anzahl ihrer Parameter ab. Diese Parameter bestimmen, wie gut das Modell gelernt hat, Zusammenhänge zu erkennen und passende Ausgaben zu erzeugen.

Was sind LLM Model Parameter?
Parameter in einem neuronalen Netz sind die Gewichte, die das Modell im Training lernt. Sie steuern, wie stark ein bestimmter Input die Ausgabe beeinflusst. Diese Parameter sind fest im Modell gespeichert und stellen das gelernte Wissen dar. Je mehr Parameter ein Modell hat, desto komplexere Muster kann es verarbeiten. Dies bedeutet jedoch auch, dass es mehr Speicherplatz und Rechenleistung benötigt.
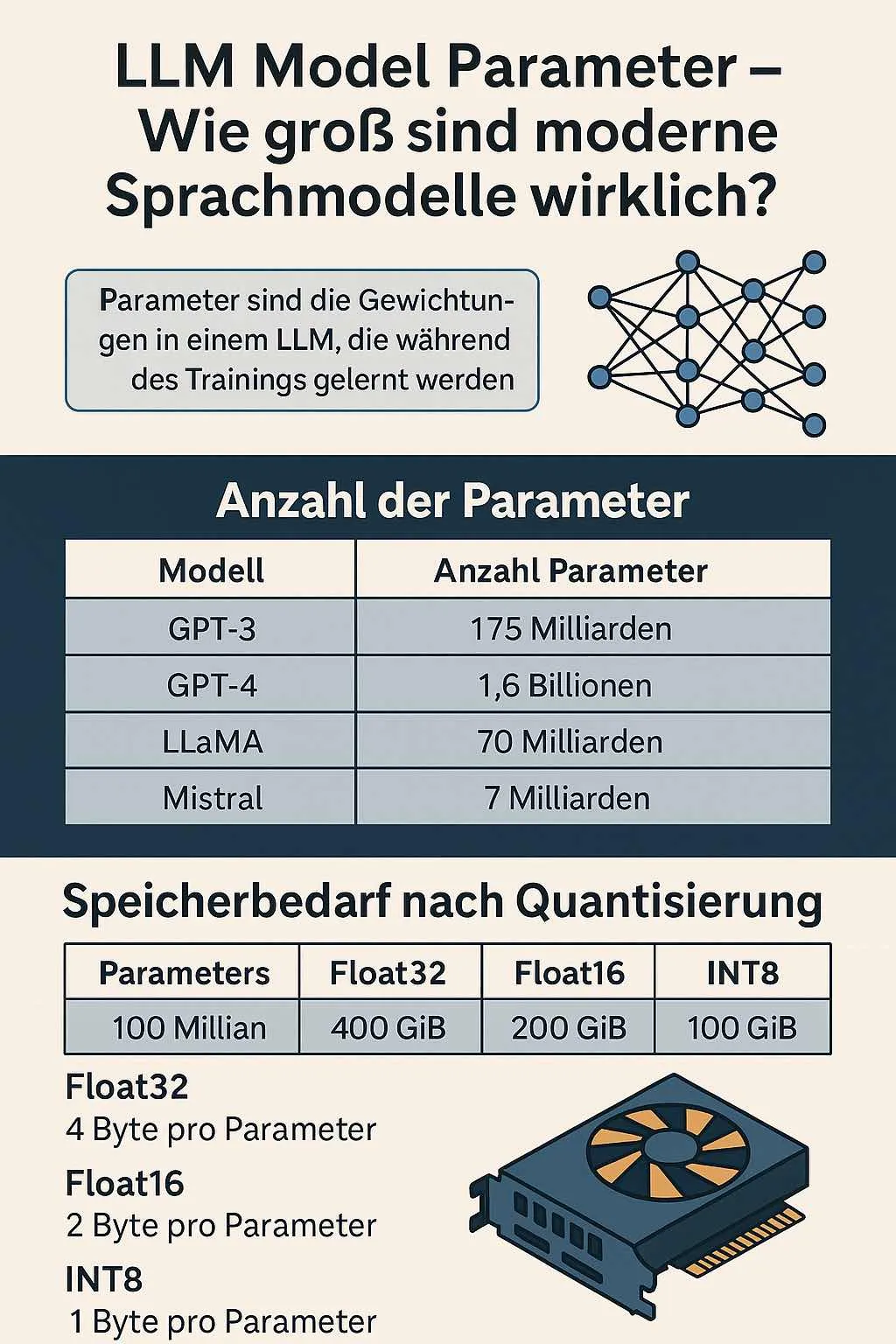
Parameteranzahl: Beispiele moderner LLMs
| Modell | Anzahl Parameter |
|---|---|
| GPT-2 | 1,5 Milliarden |
| GPT-3 | 175 Milliarden |
| GPT-4 (geschätzt) | über 500 Milliarden |
| LLaMA 2 (70B) | 70 Milliarden |
| Falcon 180B | 180 Milliarden |
| Mistral 7B | 7 Milliarden |
Parametergröße und Ressourcenbedarf
Die Größe eines Modells ergibt sich aus der Anzahl der Parameter multipliziert mit der Datenmenge pro Parameter. Die gebräuchlichsten Formate sind:
- Float32 benötigt 4 Byte pro Parameter.
- Float16 benötigt 2 Byte.
- INT8, das bei quantisierten Modellen verwendet wird, benötigt nur 1 Byte.
Beispiel:
Ein Modell mit 7 Milliarden Parametern benötigt:
- 28 GB bei Float32
- 14 GB bei Float16
- 7 GB bei INT8
Quantisierung: Weniger Bits mit fast gleicher Leistung
Quantisierung bedeutet, dass die Genauigkeit der Parameter verringert wird. Man verwendet weniger Bits pro Wert, um Speicherplatz zu sparen und die Geschwindigkeit zu erhöhen. Oft bleibt die Leistung des Modells nahezu gleich.
Vorteile:
- Reduzierter Speicherverbrauch
- Schnellere Inferenz
- Energieeffizienter
Nachteile:
- Bei starker Quantisierung kann die Genauigkeit leiden
- Nicht jedes Modell ist problemlos quantisierbar
Vergleich: Originalmodell und quantisierte Version
| Modell | Größe in Float32 | Größe in INT8 | Einsparung | Geschätzter Genauigkeitsverlust |
|---|---|---|---|---|
| LLaMA 13B | 52 GB | 13 GB | 75 % | 0,5 % bis 1,0 % |
| GPT-3 175B | 700 GB | 175 GB | 75 % | 1,0 % bis 1,5 % |
| Mistral 7B | 28 GB | 7 GB | 75 % | < 0,5 % |
Hardware-Anforderungen für LLMs
| GPU | VRAM | Modelle nutzbar (bei FP16) |
|---|---|---|
| RTX 3090 | 24 GB | Mistral 7B (INT8) |
| RTX 4090 | 24 GB | LLaMA 13B (INT8) |
| A100 80 GB | 80 GB | GPT-3 175B (teilweise) |
Single-GPU im Vergleich zu Multi-GPU-Systemen
Modelle, die mehr als 30 oder 40 GB Speicher benötigen, können nicht mehr auf gängigen einzelnen GPUs (z.B.: RTX4090) betrieben werden. Lösungen hierfür sind Multi-GPU-Setups oder die Verteilung des Modells auf mehrere Geräte (Sharding).
LoRA: Große Modelle effizient trainieren
LoRA (Low-Rank Adaptation) ist eine Methode, bei der nicht das ganze Modell trainiert wird, sondern nur kleine Adapter-Layer. Diese Layer werden zwischen den ursprünglichen Modellschichten eingefügt. Dadurch wird das Fine-Tuning extrem ressourcenschonend. Das Hauptmodell bleibt dabei unverändert. LoRA eignet sich ideal, um große LLMs auf handelsüblicher Hardware wie der RTX 3090 anzupassen.
Mixtral of Experts: Leistung nur auf Abruf
Mixtral nutzt das Prinzip der Mixture-of-Experts. Dabei wird pro Anfrage nur ein Bruchteil der Gesamtparameter genutzt. Zum Beispiel aktiviert Mixtral 8x7B bei jeder Inferenz nur zwei Experten von acht, was einer aktiven Parameteranzahl von rund 12 bis 14 Milliarden entspricht.
Vorteile:
- Reduzierter Rechenaufwand pro Anfrage
- Weniger Speicherbedarf im aktiven Zustand
- Schnellere Inferenz trotz hoher Gesamtparameterzahl
- Effizient nutzbar auf moderner Consumer-Hardware

Warum kleinere Modelle oft besser geeignet sind
Größere Modelle verbrauchen mehr Strom, sind schwieriger zu handhaben und bringen nicht immer deutlich bessere Resultate. Ein kleineres Modell wie Mistral 7B kann mit guter Feinabstimmung oft vergleichbare Ergebnisse liefern.
Zukunft der LLM Model Parameter
Die Zukunft liegt in effizienteren Architekturen wie Sparse Attention oder MoE-Modellen. Auch spezialisierte Chips und GPUs wie die kommende NVIDIA Blackwell-Serie ermöglichen es, noch größere Modelle effizienter zu betreiben.
Fazit: Was bedeuten LLM Model Parameter für dich?
Die Anzahl und Struktur der LLM Model Parameter bestimmen, ob ein Modell für deinen Anwendungsfall sinnvoll einsetzbar ist. Durch Quantisierung, LoRA und Mixtral kannst du auch große Modelle mit begrenzter Hardware effizient nutzen. Entscheidend ist die richtige Balance zwischen Leistung, Speicherbedarf und Anwendungszweck.
In diesem Artikel findest du einen Anwendungsfall für lokale LLMs. Und hier findest du einen Artikel zu relevanten Open Source LLMs.
Vorteile des decentnodes Newsletters
Als Newsletter Abonnent beibst du immer auf dem laufenden in Bezug auf neue KI und DevOps-Tools, Security Breaches etc. Außerdem bekommst du Insides zu den wichtigsten decentnodes Aha-Momenten und du erhältst ca. einmal im Monat einen Link zu unserer kostenfreien monatlichen AMA Session, wo du alle Fragen rund um die Themen KI und DevOps stellen kannst.
Hinweis: Wenn das Formular nicht funktioniert, navigiere am Ende der Website auf Cookie Einstellungen, erlaube den Cookie Brevo und lade die Seite neu.
Häufig gestellte Fragen (FAQ)
- Wie viele Parameter hat GPT-4? Die genaue Zahl ist nicht öffentlich bekannt, Schätzungen gehen von über 500 Milliarden aus.
- Kann ich ein LLM mit 13B Parametern auf einer RTX 3090 betreiben? Ja, mit INT8-Quantisierung und Optimierungstechniken ist das möglich.
- Was bedeutet FP16, FP32 und INT8? Das sind Datentypen mit unterschiedlicher Bitbreite. Sie bestimmen den Speicherverbrauch pro Parameter.
- Was bringt Quantisierung konkret? Sie reduziert Speicherbedarf und Rechenleistung, oft ohne großen Qualitätsverlust.
- Ist LoRA besser als normales Fine-Tuning? Für viele Anwendungsfälle ja, LoRA ist deutlich ressourcenschonender.
- Welche GPU ist ideal für eigene LLMs? Eine RTX 3090 oder 4090 reicht für Modelle bis ca. 13B (mit INT8). Für größere Modelle empfiehlt sich die A100 oder Cloudlösungen.